
-
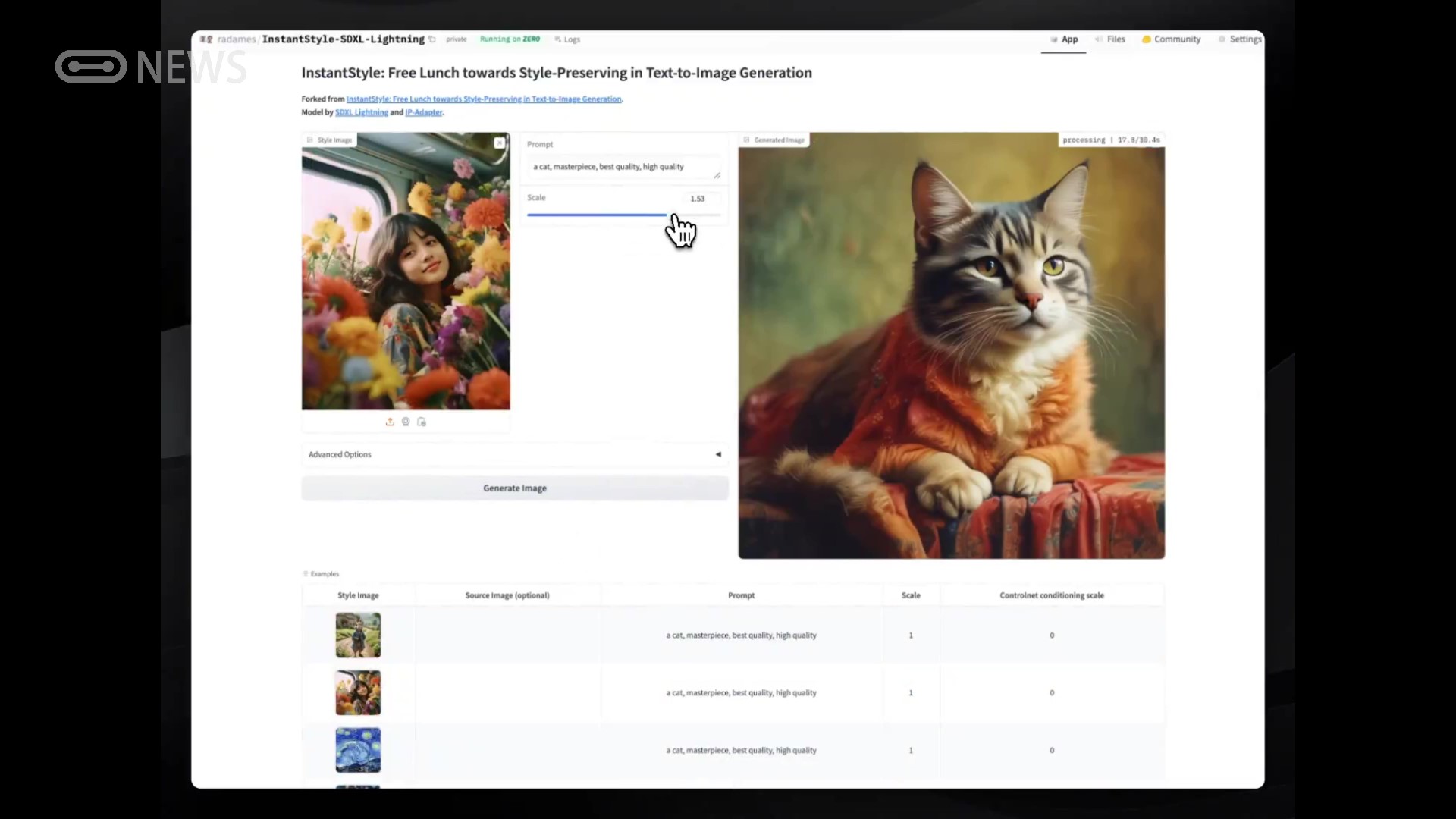
图像风格提取InstantStyle
从文本生成与样例图像风格一致的图像。Llama3免费使用:https://huggingface.co/spaces/radames/InstantStyle-SDXL-Lightning...
作者:ROBOT@qwh 日期:2024.05.15 分类:人工智能 438 -

微软静态图片视频生成框架VASA
微软公司最近推出了一种基于单一静态图像和语音音频剪辑的具有视觉情感技能(VAS)的虚拟人物逼真说话脸生成框架VASA。模型VASA-1不仅能够产生与音频同步的嘴唇动作,而且还能够捕捉到大量的面部细微差别和自然的头部动作,从而有助于感知真实性和活力。核心创新包括在面部潜在空间中工作的整体面部动力学和头部运动生成模型,以及利用视频开发这种具有表现力和解纠缠性的面部潜在空间。通过广泛的实验,包括对一组新指标的评估,我们表明我们的方法在各个方面都明显优于以前的方法。我们的方法不仅提供...
作者:ROBOT@qwh 日期:2024.04.18 分类:人工智能 1012 -

OpenAI:马斯克希望我们与特斯拉合并或“完全控制”
据称,特斯拉和SpaceX的亿万富翁首席执行官埃隆·马斯克希望人工智能研究公司OpenAI要么与特斯拉合并,要么让他完全控制该组织。OpenAI 的一篇博文回应了马斯克对该公司提起的诉讼,披露了 2015 年至 2018 年马斯克仍参与公司运营时的电子邮件通信。 据报道,在 2017 年 OpenAI 正在探索向营利性模式转型以获取更多资金的一封电子邮件中,马斯克希望获得多数股权、董事会控制权以及首席执行官职位。然而,OpenAI 认为这种由个人控制的程度有悖于其使命。“埃隆...
作者:airobotnews 日期:2024.03.07 分类:人工智能 1109 -

解析 O'Reilly 2024 年技术趋势报告
在快速发展的技术领域,跟上最新趋势对于行业中的任何人来说都至关重要。O'Reilly 2024 年技术趋势报告成为这一努力的重要指南,全面概述了最重要的技术进步和模式。这份年度报告是根据 O'Reilly 著名在线学习平台 280 万用户的使用数据精心分析的产物。它提供了一个独特的机会来了解哪些技术工具正在获得关注,哪些技术工具正在衰退,从而使领导者和专业人士能够在战略规划和技能发展方面保持领先地位。这份报告的意义不仅仅在于统计数据;它是衡量技术风向的晴雨表。通过分析数百万用...
作者:airobotnews 日期:2024.01.28 分类:人工智能 1505 -

Meta 通过 Nvidia 芯片大力投资人工智能未来
Meta 正在深入人工智能领域,这是一项雄心勃勃的举措,标志着重大战略转变。该合资企业的核心是对英伟达尖端计算机芯片的大规模投资,这是人工智能研发不可或缺的一部分。Meta 首席执行官马克·扎克伯格 (Mark Zuckerberg) 最近透露了广泛的人工智能基础设施计划,这对于公司未来的技术路线图至关重要。这项巨大的投资不仅是为了增强当前的能力,而且是 Meta 致力于在人工智能领域开拓的明确标志。使用 Nvidia 的 H100 GPU 构建强大的人工智能基础设施Meta...
作者:airobotnews 日期:2024.01.24 分类:人工智能 1366 -
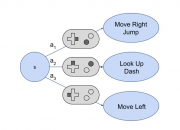
一种自动确定计算机游戏状态中可能动作的方法
由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏...
作者:ROBOT@qwh 日期:2023.12.07 分类:人工智能 1957 -

拆解 OpenAI 的新董事会
在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事...
作者:airobotnews 日期:2023.11.23 分类:人工智能 1963 -

使用语言让机器人更好地掌握开放世界
想象一下,您正在国外拜访一位朋友,您查看了他们的冰箱,看看有什么可以做一顿丰盛的早餐。许多物品一开始对您来说都是陌生的,每一件物品都装在不熟悉的包装和容器中。尽管存在这些视觉上的区别,您还是开始了解每一种的用途,并根据需要选择它们。受人类处理不熟悉物体的能力的启发,麻省理工学院计算机科学与人工智能实验室 (CSAIL) 的一个团队设计了机器人操纵特征场 (F3RM),这是一个将 2D 图像与基础模型特征混合到 3D 场景中的系统,以帮助机器人识别并抓住附近的物品。F3RM可以...
作者:airobotnews 日期:2023.11.16 分类:人工智能 429 -

CIFAR-10--人工智能数据集
由 Krizhevsky 等人提出。从微小图像中学习多层特征CIFAR -10数据集(加拿大高级研究所,10 个类别)是 Tiny Images 数据集的子集,由 60000 张 32x32 彩色图像组成。这些图像标有 10 个相互排斥的类别之一:飞机、汽车(但不是卡车或皮卡车)、鸟、猫、鹿、狗、青蛙、马、船和卡车(但不是皮卡车)。每类有 6000 张图像,每类有 5000 张训练图像和 1000 张测试图像。判断图像是否属于某个类的标准如下:类名应该位于“这张图片...
作者:ROBOT@qwh 日期:2023.11.13 分类:人工智能 455 -
热门文章
-
康普顿未来智慧农场
 康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量....
康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量.... -
拆解 OpenAI 的新董事会
在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事... -
一种自动确定计算机游戏状态中可能动作的方法
由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏... -
使用众包反馈来帮助训练机器人
 为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数...
为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数... -
HierSpeech++:通过零样本语音合成新架构
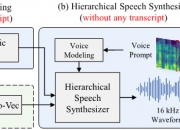 基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
