

想象一下,您正在国外拜访一位朋友,您查看了他们的冰箱,看看有什么可以做一顿丰盛的早餐。许多物品一开始对您来说都是陌生的,每一件物品都装在不熟悉的包装和容器中。尽管存在这些视觉上的区别,您还是开始了解每一种的用途,并根据需要选择它们。
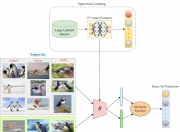
受人类处理不熟悉物体的能力的启发,麻省理工学院计算机科学与人工智能实验室 (CSAIL) 的一个团队设计了机器人操纵特征场 (F3RM),这是一个将 2D 图像与基础模型特征混合到 3D 场景中的系统,以帮助机器人识别并抓住附近的物品。F3RM可以解释人类的开放式语言提示,使得该方法在包含数千个对象(例如仓库和家庭)的现实环境中很有用。
F3RM 为机器人提供了使用自然语言解释开放式文本提示的能力,帮助机器操纵物体。因此,机器可以理解人类不太具体的请求,并仍然完成所需的任务。例如,如果用户要求机器人“拿起一个高杯子”,机器人可以找到并抓取最适合该描述的物品。
美国国家科学基金会人工智能与基础交互研究所和麻省理工学院 CSAIL 的博士后Ge Yang表示:“制造能够真正在现实世界中进行泛化的机器人非常困难。” “我们真的很想弄清楚如何做到这一点,因此通过这个项目,我们试图推动泛化的积极水平,从三四个物体到我们在麻省理工学院 Stata 中心找到的任何东西。我们想学习如何让机器人像我们一样灵活,因为我们可以抓取和放置物体,即使我们以前从未见过它们。”
学习“通过观察发现什么”
该方法可以帮助机器人在大型配送中心拣选不可避免的混乱和不可预测的物品。在这些仓库中,机器人通常会收到需要识别的库存描述。无论包装如何变化,机器人都必须匹配提供给物体的文本,以便正确运送客户的订单。
例如,主要在线零售商的履行中心可能包含数百万件商品,其中许多是机器人以前从未遇到过的。为了在如此大规模的情况下运行,机器人需要理解不同物品的几何形状和语义,其中一些物品位于狭小的空间内。凭借 F3RM 先进的空间和语义感知能力,机器人可以更有效地定位物体、将其放入垃圾箱,然后将其发送进行包装。最终,这将帮助工厂工人更有效地运送客户的订单。
“F3RM 经常让人们感到惊讶的一件事是,同一系统也适用于房间和建筑规模,并且可用于构建机器人学习和大型地图的模拟环境,”Yang 说。“但在我们进一步扩大这项工作之前,我们希望首先让这个系统运行得非常快。这样,我们就可以将这种类型的表示用于更动态的机器人控制任务,希望是实时的,以便处理更多动态任务的机器人可以使用它进行感知。”
麻省理工学院的团队指出,F3RM 理解不同场景的能力可以使其在城市和家庭环境中发挥作用。例如,该方法可以帮助个性化机器人识别并拾取特定物品。该系统帮助机器人从物理上和感知上掌握周围环境。
“视觉感知被 David Marr 定义为‘通过观察知道什么在哪里’的问题,”资深作者、麻省理工学院电气工程和计算机科学副教授兼 CSAIL 首席研究员Phillip Isola说。“最近的基础模型已经非常擅长了解他们所关注的内容;它们可以识别数千种物体类别并提供图像的详细文本描述。与此同时,辐射场已经非常擅长代表场景中物体的位置。这两种方法的结合可以创建 3D 位置的表示,我们的工作表明,这种组合对于需要在 3D 中操纵对象的机器人任务特别有用。”
创建“数字孪生”
F3RM 开始通过使用自拍杆拍照来了解周围的环境。安装的相机以不同姿势拍摄 50 张图像,使其能够构建神经辐射场(NeRF),这是一种利用 2D 图像构建 3D 场景的深度学习方法。这张 RGB 照片拼贴画以 360 度展示附近事物的形式创建了周围环境的“数字双胞胎”。
除了高度详细的神经辐射场之外,F3RM 还构建了一个特征场,以通过语义信息增强几何形状。该系统使用CLIP,这是一种经过数亿图像训练的视觉基础模型,可以有效地学习视觉概念。通过重建自拍杆拍摄图像的 2D CLIP 特征,F3RM 有效地将 2D 特征提升为 3D 表示。
保持事情的开放性
在接受了几次演示后,机器人应用其所了解的几何和语义知识来抓取以前从未遇到过的物体。一旦用户提交文本查询,机器人就会搜索可能的抓取空间,以识别那些最有可能成功拾取用户请求的物体的人。每个潜在选项的评分基于其与提示的相关性、与机器人所接受训练的演示的相似性以及是否会导致任何碰撞。然后选择并执行得分最高的抓握。
为了证明系统解释人类开放式请求的能力,研究人员提示机器人拿起迪士尼《超级英雄 6》中的角色大白。虽然 F3RM 从未接受过捡起卡通超级英雄玩具的直接训练,但该机器人利用基础模型中的空间意识和视觉语言特征来决定抓握哪个物体以及如何捡起它。
F3RM 还允许用户指定他们希望机器人在不同语言细节级别处理的对象。例如,如果有一个金属杯和一个玻璃杯,用户可以向机器人询问“玻璃杯”。如果机器人看到两个玻璃杯,其中一个装满咖啡,另一个装满果汁,则用户可以要求“装有咖啡的玻璃杯”。嵌入特征字段中的基础模型特征实现了这种级别的开放式理解。
“如果我向一个人展示如何通过嘴唇拿起杯子,他们可以轻松地将这些知识转移到拿起具有相似几何形状的物体,例如碗、量杯,甚至卷带。对于机器人来说,达到这种水平的适应性是相当具有挑战性的,”麻省理工学院博士生、CSAIL 附属机构、联合主要作者William Shen说。“F3RM 将几何理解与基于互联网规模数据训练的基础模型的语义相结合,只需少量演示即可实现这种程度的积极概括。”
Shen 和 Yang 在 Isola 的指导下撰写了这篇论文,麻省理工学院教授兼 CSAIL 首席研究员 Leslie Pack Kaelbling 以及本科生 Alan Yu 和 Jansen Wong 为共同作者。该团队得到了 Amazon.com Services、国家科学基金会、空军科学研究办公室、海军研究办公室多学科大学计划、陆军研究办公室、MIT-IBM Watson 实验室和麻省理工学院对情报的探索。他们的工作将在 2023 年机器人学习会议上展示。
版权声明
本文仅代表作者观点,不代表本网站立场。
本文系作者授权本网站发表,未经许可,不得转载。






发表评论