
语言查询音频源分离(LASS)是计算听觉场景分析(CASA)的新范例。LASS 旨在根据自然语言查询从音频混合物中分离出目标声音,这为数字音频应用程序提供了自然且可扩展的接口。最近的 LASS 工作尽管在特定源(例如乐器、有限类别的音频事件...

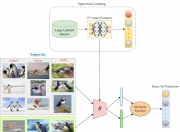
语言查询音频源分离(LASS)是计算听觉场景分析(CASA)的新范例。LASS 旨在根据自然语言查询从音频混合物中分离出目标声音,这为数字音频应用程序提供了自然且可扩展的接口。最近的 LASS 工作尽管在特定源(例如乐器、有限类别的音频事件)上取得了有希望的分离性能,但无法在开放域中分离音频概念。在这项工作中,我们介绍了 AudioSep,这是一种使用自然语言查询进行开放域音频源分离的基础模型。我们在大规模多模态数据集上训练 AudioSep,并广泛评估其在音频事件分离、乐器分离和语音增强等众多任务中的能力。AudioSep 使用音频字幕或文本标签作为查询,展示了强大的分离性能和令人印象深刻的零样本泛化能力,大大优于以前的音频查询和语言查询声音分离模型。
为了这项工作的可重复性,我们将在以下位置发布源代码、评估基准和预训练模型:https://github.com/Audio-AGI/AudioSep。
论文下载地址: https://arxiv.org/pdf/2308.05037v1.pdf
版权声明
本文仅代表作者观点,不代表本网站立场。
本文系作者授权本网站发表,未经许可,不得转载。
上一篇:OpenAI考虑加入AI芯片制造联盟 下一篇:机器人烹饪方法YORI






发表评论