
-

使用众包反馈来帮助训练机器人
为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数...
作者:ROBOT@qwh 日期:2023.11.29 分类:机器人 1818 -

OpenAI考虑加入AI芯片制造联盟
OpenAI是著名的ChatGPT背后的强大力量,可能很快就会深入研究人工智能芯片制造的动态世界。根据路透社的一份新报道,该公司正在积极考虑创建其独特的AI芯片,甚至正在考虑收购该领域的潜在目标。全球对AI芯片的需求正在飙升,尤其是在OpenAI的ChatGPT去年冲击市场之后。这种被称为AI加速器的专用芯片在培训和实施尖端的生成AI技术方面发挥着关键作用。目前,市场认为英伟达处于顶峰,在大多数AI芯片生产中占据主导地位。OpenAI对这些昂贵的芯片的依赖也是有限的,这使该公...
作者:ROBOT@qwh 日期:2023.10.12 分类:人工智能 380 -

新型的可重构机器人Tail STAR
Tail STAR是一种新型的可延展式机器人,具有双关节的尾巴,能够克服各种障碍。它可以用于搜索和救援应用。它可以穿过缝隙,爬过楼梯和人行道。它可以爬过比车轮半径大6倍的障碍物。视频: 论文:https://ieeexplore.ieee.org/document/10050748...
作者:ROBOT@qwh 日期:2023.10.07 分类:机器人 551
热门文章
-
康普顿未来智慧农场
 康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量....
康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量.... -
拆解 OpenAI 的新董事会
 在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事...
在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事... -
一种自动确定计算机游戏状态中可能动作的方法
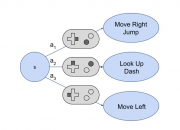 由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏...
由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏... -
使用众包反馈来帮助训练机器人
为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数... -
HierSpeech++:通过零样本语音合成新架构
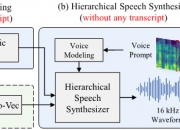 基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
