
基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文...

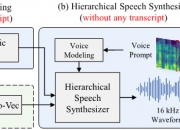
基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表示和韵律提示生成自监督语音表示和 F0 表示。然后,HierSpeech++ 根据生成的向量、F0 和语音提示生成语音。我们进一步介绍了从16 kHz到48 kHz的高效语音超分辨率框架。实验结果表明,分层变分自动编码器可以成为强大的零样本语音合成器,因为它优于基于 LLM 和基于扩散的模型。此外,我们还实现了第一个人类水平质量的零样本语音合成。
论文:https://arxiv.org/abs/2311.12454
代码仓库:https://github.com/sh-lee-prml/HierSpeechpp
代码仓库2:https://github.com/camenduru/HierSpeech_TTS-colab
一个ai API 网站:https://modelslab.com/
版权声明
本文仅代表作者观点,不代表本网站立场。
本文系作者授权本网站发表,未经许可,不得转载。
上一篇:使用众包反馈来帮助训练机器人 下一篇:一种自动确定计算机游戏状态中可能动作的方法




发表评论