
-

Zero123++:从单张图像推理出多个视图模型
Zero123++,这是一种图像条件扩散模型,用于从单个输入视图生成 3D 一致的多视图图像。为了充分利用预训练的 2D 生成先验,我们开发了各种条件和训练方案,以最大限度地减少现成图像扩散模型(例如稳定扩散)的微调工作。Zero123++ 擅长从单个图像生成高质量、一致的多视图图像,克服纹理退化和几何错位等常见问题。此外,我们展示了在 Zero123++ 上训练 ControlNet 以增强对生成过程的控制的可行性。 ...
作者:ROBOT@qwh 日期:2023.10.25 分类:人工智能 680 -

现代机器人I - 手臂式机械手(教程)
Modern Robotics I - Arm Type ManipulatorsYou can watch a video of the introduction to the Modern Robotics I course at the link below:Introduction to the Course VideoDownload the full syllabus of the course including grading criteria at the...
作者:ROBOT@qwh 日期:2023.10.24 分类:学习教程 531 -

机器人烹饪方法YORI
由加州大学洛杉矶分校的机器人与机械实验室一直在研究,既利用机器人友好的自动化,又利用人类技能,使事物味道正确,的烹饪机器人解决方案。 论文链接:https://spectrum.ieee.org/romela-cooking-robot...
作者:ROBOT@qwh 日期:2023.10.17 分类:机器人 795 -

在音频中将你的描述和内容分开模型AudioSep
语言查询音频源分离(LASS)是计算听觉场景分析(CASA)的新范例。LASS 旨在根据自然语言查询从音频混合物中分离出目标声音,这为数字音频应用程序提供了自然且可扩展的接口。最近的 LASS 工作尽管在特定源(例如乐器、有限类别的音频事件)上取得了有希望的分离性能,但无法在开放域中分离音频概念。在这项工作中,我们介绍了 AudioSep,这是一种使用自然语言查询进行开放域音频源分离的基础模型。我们在大规模多模态数据集上训练 AudioSep,并广泛评估其在音频事件分离、乐器...
作者:ROBOT@qwh 日期:2023.10.16 分类:项目 1441 -

OpenAI考虑加入AI芯片制造联盟
OpenAI是著名的ChatGPT背后的强大力量,可能很快就会深入研究人工智能芯片制造的动态世界。根据路透社的一份新报道,该公司正在积极考虑创建其独特的AI芯片,甚至正在考虑收购该领域的潜在目标。全球对AI芯片的需求正在飙升,尤其是在OpenAI的ChatGPT去年冲击市场之后。这种被称为AI加速器的专用芯片在培训和实施尖端的生成AI技术方面发挥着关键作用。目前,市场认为英伟达处于顶峰,在大多数AI芯片生产中占据主导地位。OpenAI对这些昂贵的芯片的依赖也是有限的,这使该公...
作者:ROBOT@qwh 日期:2023.10.12 分类:人工智能 379 -

重新定义机器人技术:普渡大学的创新机器视觉解决方案
受人尊敬的普渡大学的研究人员在机器人、机器视觉和感知领域取得了重大飞跃。他们的突破性方法比传统技术有了显着的改进,有望在未来机器比以往任何时候都更有效、更安全地感知周围环境。介绍HADAR:机器感知的革命性飞跃Elmore电气和计算机工程副教授Zubin Jacob与研究科学家Fanglin Bao合作,介绍了一种名为HADAR的开创性方法,是热辅助检测和测距的缩写。他们的创新引起了极大的关注,这种认可扩大了人们对HADAR在各个领域的潜在应用的预期。传统上,机器感知依赖于激...
作者:ROBOT@qwh 日期:2023.10.12 分类:机器人 376 -

与大型语言模型和机器人相关的资源、文章和观点列表
我们收集了一些与大型语言模型(LLM)相关的文章,观点,视频和资源。其中一些链接还涵盖了其他生成模型。我们将定期更新此列表,以添加任何其他感兴趣的资源。本文是该系列的第三篇。(以前的版本在这里:v1 |v2.)什么是法学硕士以及它们是如何工作的什么是生成AI模型?,Kate Soule,来自IBM Technology的视频。大型语言模型简介,John Ewald,来自Google Cloud Tech的视频。什么是 GPT-4,它与 ChatGPT 有何不同?,A...
作者:ROBOT@qwh 日期:2023.10.10 分类:人工智能 1106 -

手指形传感器使机器人更加灵巧
麻省理工学院的研究人员开发了一种基于摄像头的触摸传感器,它又长又弯曲,形状像人类的手指。他们的设备在大面积上提供高分辨率的触觉感应,可以使机器人手执行多种类型的抓取。图片:由研究人员提供作者:亚当·泽维 |麻省理工学院新闻想象一下,用一只手抓住一个重物,比如管扳手。您可能会用整个手指抓住扳手,而不仅仅是指尖。皮肤中的感觉受体沿着每个手指的整个长度运行,会向你的大脑发送有关你正在掌握的工具的信息。在机器人手中,使用摄像头获取有关抓取物体信息的触觉传感器又小又扁,因此它们通常位于...
作者:ROBOT@qwh 日期:2023.10.10 分类:机器人 476 -

机器人技术的新曙光:基于触摸的物体旋转
在一项突破性的开发中,加州大学圣地亚哥分校 (UCSD) 的工程师团队设计了一款机械手,可以仅通过触摸来旋转物体,而无需视觉输入。这种创新方法的灵感来自于人类无需看到物体即可轻松处理物体的方式。对象操纵的触摸敏感方法该团队为四指机械手配备了 16 个触摸传感器,分布在其手掌和手指上。每个传感器的成本约为 12 美元,执行一个简单的功能:检测物体是否正在接触它。这种方法是独一无二的,因为它依赖于大量低成本、低分辨率的触摸传感器,这些传感器使用简单的二进制信号(触摸或不触摸)来执...
作者:ROBOT@qwh 日期:2023.10.09 分类:机器人 443 -

“无脑”软机器人在复杂环境中导航机器人技术突破
在不断发展的机器人领域,研究人员实现了一项新的突破:一种不需要人类或计算机指导即可在复杂环境中导航的软机器人。这项新发明建立在之前的工作基础上,其中软机器人在更简单的迷宫中展示了基本的导航技能。利用物理智能进行导航该研究的共同通讯作者、北卡罗来纳州立大学机械与航空航天工程副教授尹杰阐述了这一进展:“在我们早期的工作中,我们证明了我们的软机器人能够扭转和转弯通过一个非常简单的障碍路线。然而,除非遇到障碍物,否则它无法转弯。这种限制意味着机器人有时可能会被困在平行障碍物之间来回弹...
作者:ROBOT@qwh 日期:2023.10.09 分类:机器人 368
热门文章
-
康普顿未来智慧农场
 康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量....
康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量.... -
拆解 OpenAI 的新董事会
 在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事...
在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事... -
一种自动确定计算机游戏状态中可能动作的方法
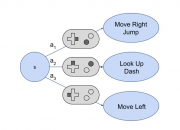 由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏...
由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏... -
使用众包反馈来帮助训练机器人
 为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数...
为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数... -
HierSpeech++:通过零样本语音合成新架构
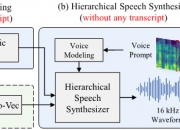 基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
