
-

使用语言让机器人更好地掌握开放世界
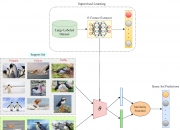
想象一下,您正在国外拜访一位朋友,您查看了他们的冰箱,看看有什么可以做一顿丰盛的早餐。许多物品一开始对您来说都是陌生的,每一件物品都装在不熟悉的包装和容器中。尽管存在这些视觉上的区别,您还是开始了解每一种的用途,并根据需要选择它们。受人类处理不熟悉物体的能力的启发,麻省理工学院计算机科学与人工智能实验室 (CSAIL) 的一个团队设计了机器人操纵特征场 (F3RM),这是一个将 2D 图像与基础模型特征混合到 3D 场景中的系统,以帮助机器人识别并抓住附近的物品。F3RM可以...
作者:airobotnews 日期:2023.11.16 分类:人工智能 430 -

-

CIFAR-10--人工智能数据集
由 Krizhevsky 等人提出。从微小图像中学习多层特征CIFAR -10数据集(加拿大高级研究所,10 个类别)是 Tiny Images 数据集的子集,由 60000 张 32x32 彩色图像组成。这些图像标有 10 个相互排斥的类别之一:飞机、汽车(但不是卡车或皮卡车)、鸟、猫、鹿、狗、青蛙、马、船和卡车(但不是皮卡车)。每类有 6000 张图像,每类有 5000 张训练图像和 1000 张测试图像。判断图像是否属于某个类的标准如下:类名应该位于“这张图片...
作者:ROBOT@qwh 日期:2023.11.13 分类:人工智能 455 -
-

DevOps 中的 AI:简化软件部署和运营
就像一台运转良好的机器一样,您的组织正处于重大软件部署的边缘。您已经在尖端人工智能解决方案上投入了大量资金,您的数字化转型战略已经制定,并且您的目光坚定地瞄准了未来。然而,问题迫在眉睫——您能否真正利用人工智能的力量来简化软件部署和运营?到 2027 年,全球数字化转型市场规模将达到惊人的15,489 亿美元,复合年增长率为 21.1%,您不能只是原地踏步。 随着新兴的DevOps 趋势重新定义软件开发,公司利用先进的功能来加速人工智能的采用。这就是为什么,您需要拥...
作者:ROBOT@qwh 日期:2023.11.01 分类:人工智能 467 -

Zero123++:从单张图像推理出多个视图模型
Zero123++,这是一种图像条件扩散模型,用于从单个输入视图生成 3D 一致的多视图图像。为了充分利用预训练的 2D 生成先验,我们开发了各种条件和训练方案,以最大限度地减少现成图像扩散模型(例如稳定扩散)的微调工作。Zero123++ 擅长从单个图像生成高质量、一致的多视图图像,克服纹理退化和几何错位等常见问题。此外,我们展示了在 Zero123++ 上训练 ControlNet 以增强对生成过程的控制的可行性。 ...
作者:ROBOT@qwh 日期:2023.10.25 分类:人工智能 684 -

现代机器人I - 手臂式机械手(教程)
Modern Robotics I - Arm Type ManipulatorsYou can watch a video of the introduction to the Modern Robotics I course at the link below:Introduction to the Course VideoDownload the full syllabus of the course including grading criteria at the...
作者:ROBOT@qwh 日期:2023.10.24 分类:学习教程 534 -

机器人烹饪方法YORI
由加州大学洛杉矶分校的机器人与机械实验室一直在研究,既利用机器人友好的自动化,又利用人类技能,使事物味道正确,的烹饪机器人解决方案。 论文链接:https://spectrum.ieee.org/romela-cooking-robot...
作者:ROBOT@qwh 日期:2023.10.17 分类:机器人 797 -

在音频中将你的描述和内容分开模型AudioSep
语言查询音频源分离(LASS)是计算听觉场景分析(CASA)的新范例。LASS 旨在根据自然语言查询从音频混合物中分离出目标声音,这为数字音频应用程序提供了自然且可扩展的接口。最近的 LASS 工作尽管在特定源(例如乐器、有限类别的音频事件)上取得了有希望的分离性能,但无法在开放域中分离音频概念。在这项工作中,我们介绍了 AudioSep,这是一种使用自然语言查询进行开放域音频源分离的基础模型。我们在大规模多模态数据集上训练 AudioSep,并广泛评估其在音频事件分离、乐器...
作者:ROBOT@qwh 日期:2023.10.16 分类:项目 1443 -

OpenAI考虑加入AI芯片制造联盟
OpenAI是著名的ChatGPT背后的强大力量,可能很快就会深入研究人工智能芯片制造的动态世界。根据路透社的一份新报道,该公司正在积极考虑创建其独特的AI芯片,甚至正在考虑收购该领域的潜在目标。全球对AI芯片的需求正在飙升,尤其是在OpenAI的ChatGPT去年冲击市场之后。这种被称为AI加速器的专用芯片在培训和实施尖端的生成AI技术方面发挥着关键作用。目前,市场认为英伟达处于顶峰,在大多数AI芯片生产中占据主导地位。OpenAI对这些昂贵的芯片的依赖也是有限的,这使该公...
作者:ROBOT@qwh 日期:2023.10.12 分类:人工智能 380
热门文章
-
康普顿未来智慧农场
 康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量....
康普顿未来农场,使用更少的水和1%的土地,即可实现与产统农业相同产量.... -
拆解 OpenAI 的新董事会
 在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事...
在人工智能和技术领域掀起波澜的惊人事件中,人工智能领域的领先实体 OpenAI 最近的领导地位发生了重大转变。以萨姆·奥尔特曼 (Sam Altman) 戏剧性地重返首席执行官职位以及随之而来的董事会改组为标志,这些变化代表了该组织的关键时刻。OpenAI 以其在人工智能研究和开发方面的开创性工作而闻名,包括广泛认可的 ChatGPT 和 DALL-E 模型,站在人工智能进步的最前沿。因此,董事会的重组不仅仅是人员的变动,还标志着人工智能领域最具影响力的组织之一的方向、优先事... -
一种自动确定计算机游戏状态中可能动作的方法
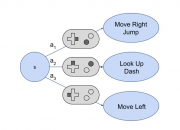 由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏...
由于手动彻底测试视频游戏软件非常困难,因此需要拥有能够自动探索不同游戏功能的人工智能代理。此类代理的关键要求是玩家动作的模型,代理可以使用该模型来确定不同游戏状态下的可能动作集,以及对代理策略选择的游戏执行选定的动作。目前使用的典型游戏引擎不提供这样的动作模型,导致现有的工作要么需要人工手动定义动作模型,要么不精确地猜测可能的动作。在我们的工作中,我们通过为游戏中存在的用户输入处理逻辑开发最先进的分析方法来演示程序分析如何有效解决该问题,该分析可以使用离散动作空间自动建模游戏... -
使用众包反馈来帮助训练机器人
 为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数...
为了教人工智能代理一项新任务,比如如何打开厨房柜子,研究人员经常使用强化学习——这是一种试错过程,在该过程中,代理会因采取更接近目标的行动而获得奖励。在许多情况下,人类专家必须仔细设计奖励函数,这是一种激励机制,赋予代理人探索的动力。当智能体探索并尝试不同的动作时,人类专家必须迭代地更新奖励函数。这可能非常耗时、效率低下,并且难以扩展,尤其是当任务复杂且涉及许多步骤时。来自麻省理工学院、哈佛大学和华盛顿大学的研究人员开发了一种新的强化学习方法,该方法不依赖于专门设计的奖励函数... -
HierSpeech++:通过零样本语音合成新架构
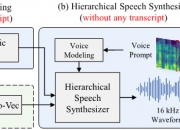 基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
基于大语言模型(LLM)的语音合成已广泛应用于零样本语音合成中。然而,它们需要大规模数据,并且具有与以前的自回归语音模型相同的局限性,包括推理速度慢和缺乏鲁棒性。本文提出了 HierSpeech++,一种快速、强大的零样本语音合成器,用于文本到语音(TTS)和语音转换(VC)。我们验证了分层语音合成框架可以显着提高合成语音的鲁棒性和表现力。此外,即使在零样本语音合成场景中,我们也显着提高了合成语音的自然度和说话人相似度。对于文本到语音,我们采用文本到向量框架,该框架根据文本表...
